

Kubernetes has become the de facto way to schedule and manage services in medium and large enterprises. Coupled with the microservice design pattern, it has proved to be a useful tool for managing everything from websites to data processing pipelines. But the ecosystem at large agrees that Kubernetes has a cost problem. Unfortunately, the predominant way to cut costs is itself a liability.
The problem is not Kubernetes. The problem is the way we build applications.
Why Kubernetes costs so much
I have been around the Kubernetes community since the very early days, and one of the early perceived benefits of Kubernetes was cost savings. We believed that we were building a system that would help manage cost by reducing the number of virtual machines that were being used. We were definitely correct in that assumption… but potentially incorrect that this would lead over the long term to cost savings. In fact, the prevailing attitude these days is that Kubernetes is in fact very expensive to run.
Did something go wrong?
The short answer is that, no, nothing went wrong. In fact, Kubernetes’ way of seeing the world has been so successful that it has changed the way we think about deploying and maintaining apps. And Kubernetes itself got considerably more sophisticated than it was in those early days. Likewise, the microservice design pattern became widely deployed—so much so that most of the time we don’t even think about the fact that we now write small services by default instead of the monolithic super-applications that were popular before containers.
It is fair to say that cost savings was always a “side benefit” of Kubernetes, not a design goal. If that narrative fell by the wayside, it’s not because Kubernetes abandoned a goal. It’s because it just proved not to be true as the entire model behind Kubernetes evolved and matured.
This is where we can talk about why Kubernetes went from “cheaper” to “very expensive.”
Kubernetes was considered cheaper than running a system in which every microservice ran on its own VM. And perhaps given the economics of the time, it was. But that sort of setup is no longer a useful comparison. Because Kubernetes has systematized platforms, and this changes the economy of cloud computing.
The cost of container reliability
Early on, Kubernetes introduced the idea of the Replication Controller, which later became Deployments and ReplicaSets. All of these abstractions were designed to handle a shortcoming of containers and virtual machines: Containers and VMs are slow to start. And that makes them liabilities during failover scenarios (when a node dies) or scale-up events (when traffic bumps up enough that current instances can’t handle the load).
Once upon a time, in the pre-Kubernetes days, we handled this by pre-provisioning servers or virtual machines and then rotating those in and out of production. Kubernetes’ replication made it possible to easily declare “I need three instances” or “I need five instances,” and the Kubernetes control plane would manage all of these automatically—keeping them healthy, recovering from failure, and gracefully handling deployments.
But this is the first place where Kubernetes started to get expensive. To handle scaling and failure, Kubernetes ran N instances of an app, where N tends to be at least three, but often five or more. And a key aspect of this replication is that the apps should be spread across multiple cluster nodes. This is because:
- If a node dies, is rebooted, or stops responding, any containers scheduled on that node become unavailable. So Kubernetes routes traffic to container instances on other nodes.
- As traffic picks up, load is distributed (somewhat) equally among all of the running instances. So no one container should buckle under load while others sit idle.
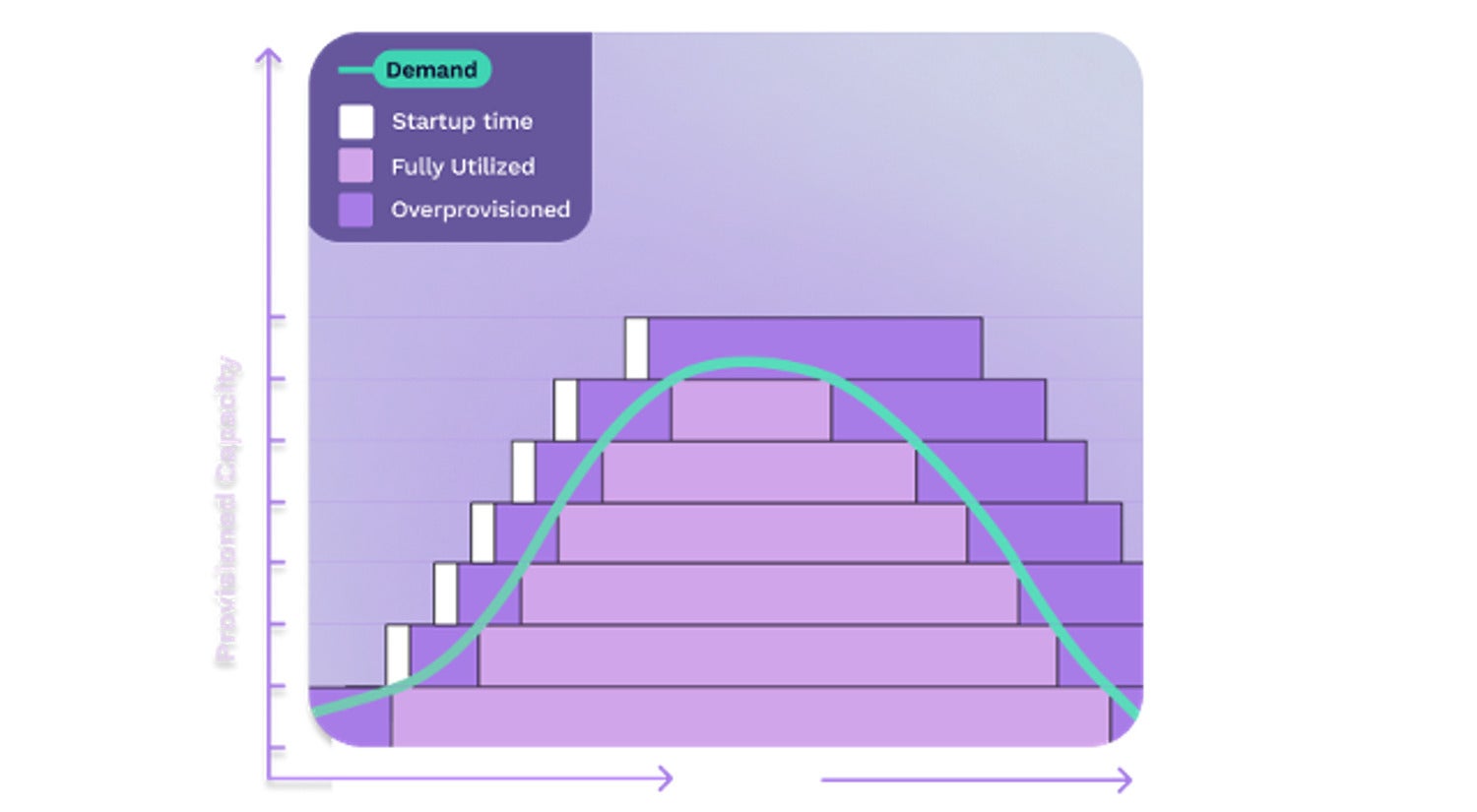
What this means is that, at any time, you are paying to run three, five, or more instances of your app. Even if the load is really low and failures are infrequent, you need to be prepared for a sudden spike in traffic or an unexpected outage. And that means always keeping spare capacity online. This is called overprovisioning.
 Fermyon
FermyonAutoscalers, introduced a little later in Kubernetes’ existence, improved the situation. Autoscalers watch for things like increased network or CPU usage and automatically increase capacity. A Horizontal Pod Autoscaler (the most popular Kubernetes autoscaler) simply starts more replicas of your app as the load picks up.
However, because containers are slow to start (taking seconds or minutes) and because load is unpredictable by nature, autoscalers have to trigger relatively early and terminate excess capacity relatively late. Are they a cost savings? Often yes. Are they a panacea? No. As the graph above illustrates, even when autoscalers anticipate increased traffic, wastage occurs both upon startup and after load decreases.
Sidecars are resource consumers
But replicas are not the only thing that makes Kubernetes expensive. The sidecar pattern also contributes. A pod may have multiple containers running. Typically, one is the primary app, and the other containers are assistive sidecars. One microservice may have separate sidecars for data services, for metrics gathering, for scaling, and so on. And each of these sidecars requires its own pool of memory, CPU, storage, etc.
Again, we shouldn’t necessarily look at this as something bad. This sort of configuration demonstrates how powerful Kubernetes is. An entire operational envelope can be wrapped around an application in the form of sidecars. But it is worth noting that now one microservice could have four or five sidecars, which means when you are running five replicas, you are now running around 25 or 30 containers.
This results in platform engineers needing not only to scale out their clusters (adding more nodes), but also to beef up the memory and CPU capacity of existing nodes.
‘Cost control’ should not be just an add-on
When cloud first found its footing, the world economy was well on its way to recovering from the 2007 recession. By 2015, when Kubernetes came along, tech was in a boom period. It wasn’t until late 2022 that economic pressures really started to push downward on cloud cost. Cloud matured in a time when cost optimization was not a high priority.
By 2022, our current cloud design patterns had solidified. We had accepted “expensive” in favor of “robust” and “fault tolerant.” Then the economy took a dip. And it was time for us to adjust our cloud spending patterns.
Unsurprisingly, an industry evolved around the problem. There are at least a dozen cost optimization tools for Kubernetes. And they espouse the idea that cost can be controlled by (a) rightsizing the cluster, and (b) buying cheap compute whenever possible.
An appropriate analogy may be the gasoline guzzling car. To control cost, we might (a) fill the tank only half full knowing we don’t need the full tank right now and (b) buy cheaper gasoline whenever we see the gasoline station drop prices low enough.
I’m not suggesting this is a bad strategy for the “car” we have today. If cloud had grown up during a time of more economic pressure, Kubernetes probably would have built these features into the core of the control plane, just as gasoline-powered cars today are more fuel efficient than those built when the price of gasoline was low.
But to extend our metaphor, maybe the best solution is to switch from a gasoline engine to an EV. In the Kubernetes case, this manifests as switching from an entirely container-based runtime to using something else.
Containers are expensive to run
We built too much of our infrastructure on containers, and containers themselves are expensive to run. There are three compounding factors that make it so:
- Containers are slow to start.
- Containers consume resources all the time (even when not under load).
- As a format, containers are bulkier than the applications they contain.
Slow to start: A container takes several seconds, or perhaps a minute, to totally come online. Some of this is low-level container runtime overhead. Some is just the cost of starting up and initializing a long-running server. But this is slow enough that a system cannot react to scaling needs. It must be proactive. That is, it must scale up in anticipation of load, not as a result of load.
Consuming resources: Because containers are slow to start, the version of the microservice architecture that took hold in Kubernetes suggests that each container holds a long-running (hours to days or even months) software server (aka a daemon) that runs continuously and handles multiple simultaneous requests. Consequently, that long-running server is always consuming resources even when it is not handling load.
Bulky format: In a sense, bulkiness is in the eye of the beholder. Certainly a container is small compared to a multi-gigabyte VM image. But when your 2 MB microservice is packaged in a 25 MB base image, that image will incur more overhead when it is moved, when it is started, and while it is running.
If we could reduce or eliminate these three issues, we could drive the cost of running Kubernetes way down. And we could hit efficiency levels that no cost control overlay could hope to achieve.
Serverless and WebAssembly provide an answer
This is where the notion of serverless computing comes in. When I talk about serverless computing, what I mean is that there is no software server (no daemon process) running all the time. Instead, a serverless app is started when a request comes in and is shut down as soon as the request is handled. Sometimes such a system is called event-driven processing because an event (like an HTTP request) starts a process whose only job is to handle that event.
Existing systems that run in (approximately) this way are: AWS Lambda, OpenWhisk, Azure Functions, and Google Cloud Functions. Each of those systems has its strengths and weaknesses, but none is as fast as WebAssembly, and most of them cannot run inside of Kubernetes. Let’s take a look at what a serverless system needs in order to work well and be cost efficient.
When a cluster processes a single request for an app, the lifecycle looks like this:
- An instance of the app is started and given the request.
- The instance runs until it returns a response.
- The instance is shut down and resources are freed.
Serverless apps are not long-running. Nor does one app handle multiple requests per instance. If 4,321 concurrent requests come in, then 4,321 instances of the app are spawned so that each instance can handle exactly one request. No process should run for more than a few minutes (and ideally less than half a second).
Three characteristics become very important:
- Startup speed must be supersonic! An app must start in milliseconds or less.
- Resource consumption must be minimal. An app must use memory, CPU, and even GPU sparingly, locking resources for the bare minimum amount of time.
- Binary format must be as small as possible. Ideally, the binary includes only the application code and the files it directly needs access to.
Yet the three things that must be true for an ideal serverless platform are weaknesses for containers. We need a different format than the container.
WebAssembly provides this kind of profile. Let’s look at an existing example. Spin is an open source tool for creating and running WebAssembly applications in the serverless (or event-driven) style. It cold starts in under one millisecond (compared to the several dozen seconds or more it takes to start a container). It uses minimal system resources, and it can often very effectively time-slice access to those resources.
For example, Spin consumes CPU, GPU, and memory only when a request is being handled. Then the resources are immediately freed for another app to use. And the binary format of WebAssembly is svelte and compact. A 2 MB application is, in WebAssembly, about 2 MB. Not a lot of overhead is added like it is with containers.
Thus we can use a technique called underprovisioning, in which we allocate fewer resources per node than we would need to simultaneously run all of the apps at full capacity. This works because we know that it will never be the case that all of the apps will be running at full capacity.
This is where we start to see how the design of serverless itself is inherently more cost-effective.
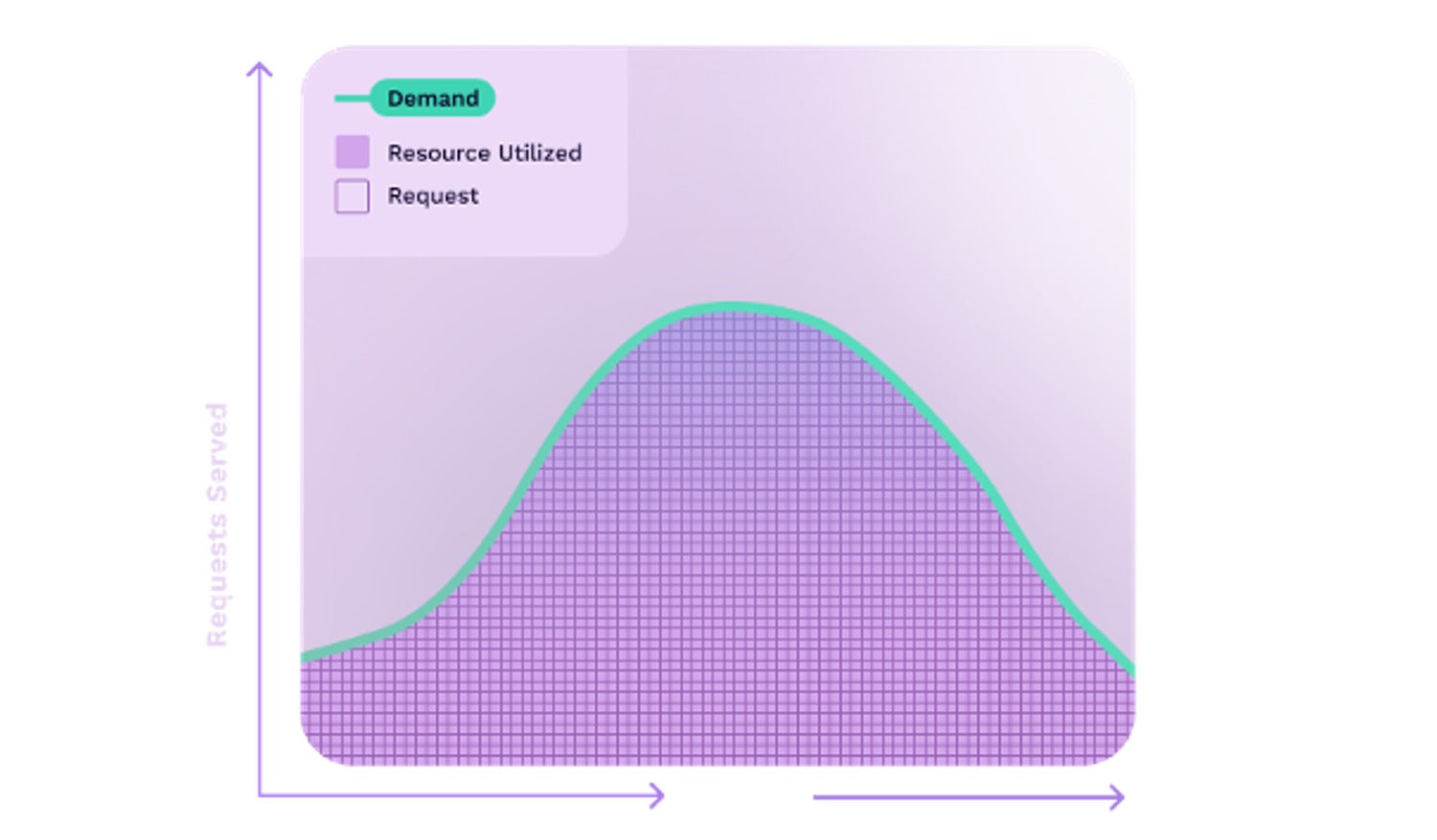 Fermyon
FermyonCompute capacity scales in lockstep with demand, as each serverless app is invoked just in time to handle a request, and then it is instantly shut down. Using a truly serverless technology like Spin and WebAssembly, we can save a lot of money inside of our Kubernetes clusters by keeping resource allocation optimized automatically.
Attaining this state comes with some work. Instead of long-running daemon processes, we must write serverless functions that each handle the work of a microservice. One serverless app (e.g. a Spin app) may implement multiple functions, with each function being a WebAssembly binary. That is, we may in fact have even smaller services than the microservice architecture typically produces. But that makes them even cheaper to run and even easier to maintain!
Using this pattern is the fastest route to maximizing the efficiency of your cluster while minimizing the cost.
Saving with Kubernetes
There are some cloud workloads that are not a good fit for serverless. Typically, databases are better operated in containers. They operate more efficiently in long-running processes where data can be cached in memory. Starting and stopping a database for each request can incur stiff performance penalties. Services like Redis (pub/sub queues and key/value storage) are also better managed in long-running processes.
But web applications, data processing pipelines, REST services, chat bots, websites, CMS systems, and even AI inferencing are cheaper to create and operate as serverless applications. Therefore, running them inside of Kubernetes with Spin will save you gobs of money over the long run.
WebAssembly presents an alternative to containers, achieving the same levels of reliability and robustness, but at a fraction of the cost. Using a serverless application pattern, we can underprovision cluster resources, squeezing every last drop of efficiency out of our Kubernetes nodes.
Matt Butcher is co-founder and CEO of Fermyon, the serverless WebAssembly in the cloud company. He is one of the original creators of Helm, Brigade, CNAB, OAM, Glide, and Krustlet. He has written and co-written many books, including “Learning Helm” and “Go in Practice.” He is a co-creator of the “Illustrated Children’s Guide to Kubernetes’ series. These days, he works mostly on WebAssembly projects such as Spin, Fermyon Cloud, and Bartholomew. He holds a Ph.D. in philosophy. He lives in Colorado, where he drinks lots of coffee.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
