

If you define your infrastructure as code, shouldn’t your workflow automation use the same as-code approach? That’s how Flowpipe works. Define workflows with HCL (HashiCorp configuration language), then run them using a single binary that you deploy locally, in the cloud, or in any CI/CD pipeline. Flowpipe embodies the same architectural ingredients you’ll find in any workflow tool: pipelines, steps, triggers, control flow. And it integrates with everything you’d expect from a tool in this category.
But this isn’t ClickOps. You don’t use a diagramming tool to build integrations. Pipeline definitions are code artifacts that live in repositories as first-class citizens of the modern software ecosystem: version-controlled and collaborative.
These pipelines can orchestrate workflows using a range of methods. Do you need to track open issues in GitHub and then notify Slack? There’s more than one way to gather the GitHub data you’ll send to Slack:
- In a pipeline step. Use the GitHub library’s
list_issuespipeline, which encapsulates an http step that calls the GitHub API. - In a query step. Use Steampipe’s GitHub plugin to query for open issues in a repo.
- In a function step. Write an AWS-Lambda-compatible function, in Python or JavaScript, to call the GitHub API.
- In a container step, package the GitHub CLI in a container and run
gh issue listthat way.
Why all these choices? The old Perl mantra “There is more than one way to do it” applies here too. Flowpipe is a modern incarnation of “duct tape for the Internet”: a flexible kit full of useful tools that work well together. For any given integration, choose the ones most appropriate in that context, or that leverage existing assets, or that are most convenient. You’re never blocked. There’s always a way to get the job done as you navigate a complex landscape of diverse and interconnected clouds and services.
Show me the code!
Here are four ways to gather information about GitHub issues.
List GitHub issues using Flowpipe’s GitHub and Slack libraries
Flowpipe mods provide reusable pipelines. In this case, there are library mods with support for both needed operations: listing GitHub issues, notifying Slack. So we can just use those libraries in a pair of pipeline steps.
pipeline "list_open_issues_and_notify_slack" {
step "pipeline" "list_issues" {
pipeline = github.pipeline.list_issues # use the github library mod
args = {
issue_state: "OPEN"
repository_owner: "turbot"
repository_name: "steampipe"
}
}
step "pipeline" "notify_slack" {
pipeline = slack.pipeline.post_message # use the github slack mod
args = {
token = var.slack_token
channel = var.slack_channel
message = step.pipeline.list_issues.value
}
}
The documentation for the GitHub and Slack mods lists available pipelines and, for each pipeline, the required and optional parameters. It’s straightforward to use published Flowpipe mods, and equally straightforward to create and use your own.
List GitHub issues using Steampipe’s GitHub plugin
Flowpipe doesn’t require Steampipe but will happily embrace it. If you’re able to use both together you gain immense power. The GitHub plugin is just one of many wrappers for a growing ecosystem of data sources, each modeled as tables you can query with SQL in a query step.
pipeline "list_open_issues_and_notify_slack" {
step "query" "query_list_issues" {
connection_string = "postgres://steampipe@localhost:9193/steampipe"
sql = <<EOQ
select * from github_issue
where repository_full_name = 'turbot/steampipe'
and state = 'OPEN'
EOQ
}
step "pipeline" "notify_slack" {
# use the library mod as above, or another method
}
}
All you need here is a connection string, by the way. If you connect to Steampipe you can tap into its plugin ecosystem, but if the data you’re going after happens to live in another database you can use SQL to query it from there.
List GitHub issues using a Lambda-compatible function
What if there’s neither a library mod nor a Steampipe plugin for your use case? Another option: Call a function in a function step.
pipeline "list_open_issues_and_notify_slack" {
step "function" "list_issues" {
src = "./functions"
runtime = "python:3.10"
handler = "list_issues.handler"
event = {
owner = "turbot"
repo = "steampipe"
}
}
Here’s the function.
def handler(event, context):
owner = event['owner']
repo = event['repo']
url = f"https://api.github.com/repos/{owner}/{repo}/issues?state=closed"
response = requests.get(url)
return {
'issues': response.json()
}
These functions, which you can write in Python or JavaScript, are compatible with AWS Lambda functions: event-driven, stateless, short-lived. And compared to AWS Lambda functions, they’re much easier to write and test. You can even live-edit your functions because when you make changes Flowpipe automatically detects and applies them.
List GitHub issues using the GitHub CLI
Command-line interfaces are fundamental tools for DevOps integration. You can package a CLI in a container and use it in a container step.
pipeline "list_open_issues_and_notify_slack" {
step "container" "list_issues" {
image = "my-gh-image"
cmd = ["/container-list-issues.sh"]
env = {
GITHUB_TOKEN = var.access_token
GH_COMMAND = var.gh_command
}
}
That’s probably overkill in this case, but the ability to use containerized commands in this way ensures maximal flexibility and portability.
Why HashiCorp configuration language?
HashCorp configuration language (HCL) is, first of all, familiar to devops pros who use it to express Terraform configurations. But the language turns out to be an ideal fit for workflow too. The directed acyclic graph (DAG) at the core of its execution model determines the order of operations based on resource dependencies, unlike many scripting languages where such dependencies must be managed explicitly.
If the second step in a workflow refers to the output of the first step, Flowpipe implicitly sequences the steps. Concurrency is implicit too. Workflow steps that don’t depend on other steps automatically run in parallel, no special syntax required. So you can create complex and highly parallel workflows in a declarative style that’s easy to read and write. For example, here’s a step that iterates over a list of users and uses an http step to call an API for each user.
step "http" "add_a_user" {
for_each = ["Jerry", "Elaine", "Newman"]
url = "https://myapi.local/api/v1/user"
method = "post"
request_body = jsonencode({
user_name = "${each.value}"
})
}
Because things don’t always go according to plan, Flowpipe’s declarative style extends to error handling and retries.
step "http" "my_request" {
url = "https://myapi.local/subscribe"
method = "post"
body = jsonencode({
name = param.subscriber
})
retry {
max_attempts = 5
strategy = "exponential"
min_interval = 100
max_interval = 10000
}
}
You’ll typically need to unpack the results of one step in a pipeline, then transform the data in order to feed it to a next step. Among the Terraform-compatible HCL functions supported by Flowpipe are collection functions that work with lists and maps.
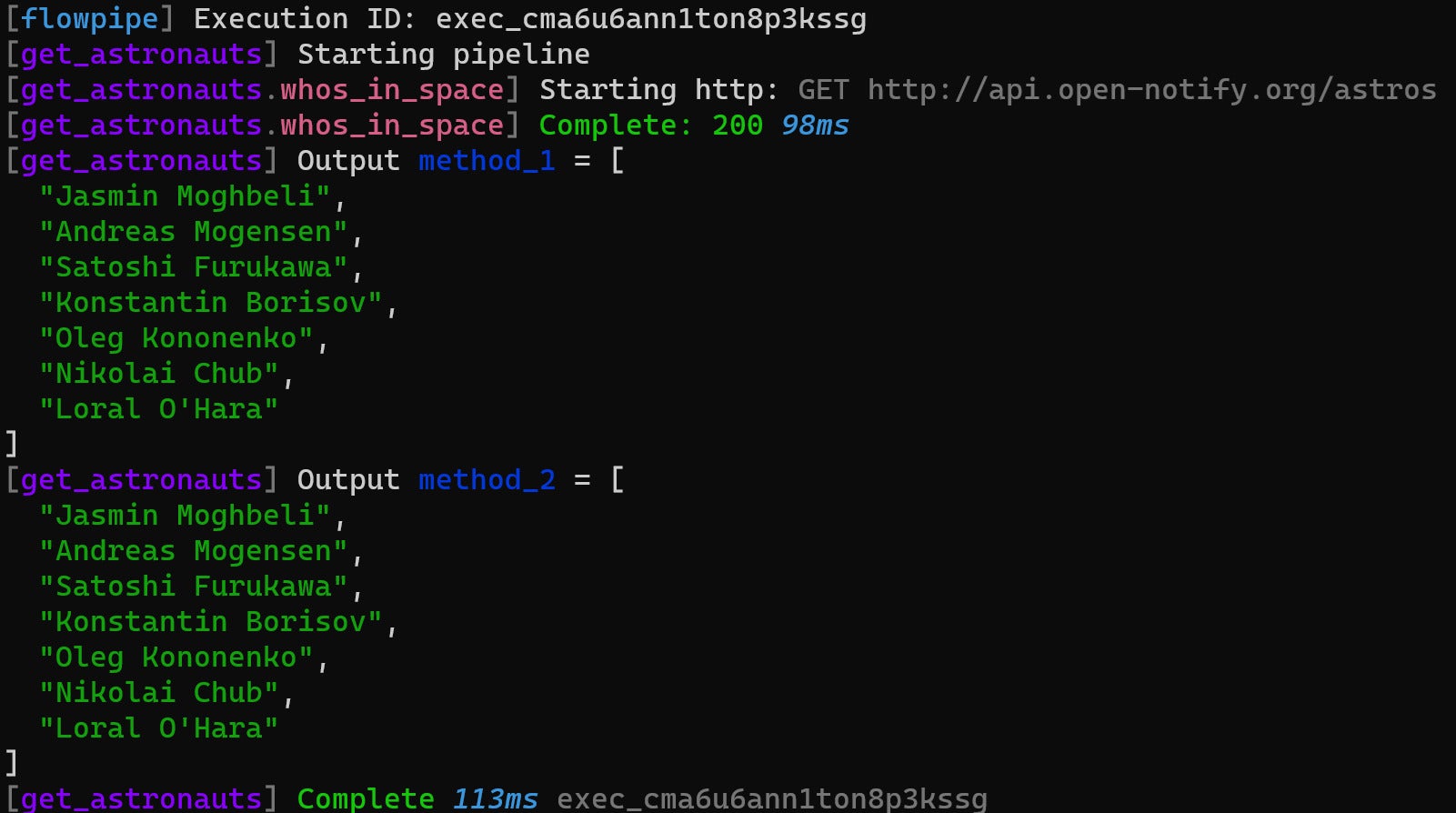
pipeline "get_astronauts" {
step "http" "whos_in_space" {
url = "http://api.open-notify.org/astros"
method = "get"
}
output "method_1" {
value = [for o in step.http.whos_in_space.response_body.people: po.name]
}
output "method_2" {
value = step.http.whos_in_space.response_body.people[*].name
}
}
Here’s the output of the command flowpipe pipeline run get_astronauts.
 IDG
IDGThe two methods are equivalent ways to iterate over the list of maps returned from the API and extract the name field from each. The first method uses the versatile for expression which can work with lists, sets, tuples, maps, and objects. The second method gives an identical result using the splat expression, which can simplify access to fields within elements of lists, sets, and tuples.
Schedules, events, and triggers
As with other workflow engines, you can trigger a Flowpipe pipeline on a cron-defined schedule.
trigger "schedule" "daily_3pm" {
schedule = "* 15 * * *"
pipeline = pipeline.daily_task
}
But you’ll also want to react immediately to events like code pushes, infrastructure change, or Slack messages. So Flowpipe provides an HTTP-based trigger to react to an incoming webhook by running a pipeline.
trigger "http" "my_webhook" {
pipeline = pipeline.my_pipeline
args = {
event = self.request_body
}
}
To use triggers, run Flowpipe in server mode.
The Goldilocks zone
Flowpipe occupies a middle ground between tools like Zapier or IFTTT, which require little or no code for simple things, and tools like N8N or Windmill, which can do complex things but require a lot of code. You express pipelines, steps, and triggers in the standard devops configuration language: HCL. As needed you augment that code with SQL, or Python, or JavaScript, or bash, or anything you can package into a container.
You coordinate all those resources using a common execution model embedded in a single binary that runs as a CLI, and/or as server that schedules tasks and listens for webhooks. Either way you can run that single binary locally or deploy it to any cloud or CI/CD pipeline.
To get started, download the tool, check out the library mods and samples, and run through the tutorial.
Will Flowpipe’s declarative code-forward style resonate with devops scripters? Give it a try and let us know how it goes. And if you’re inclined to contribute to Flowpipe’s AGPL-licensed engine or Apache-licensed mods, we are always happy to receive pull requests!
